许多我们熟悉的技术,例如alpha go,就用到了RL的技术。现在我来简单学习一下RL,目的是有一个基本的认识。
概述
回顾
对比一下supervised learning,
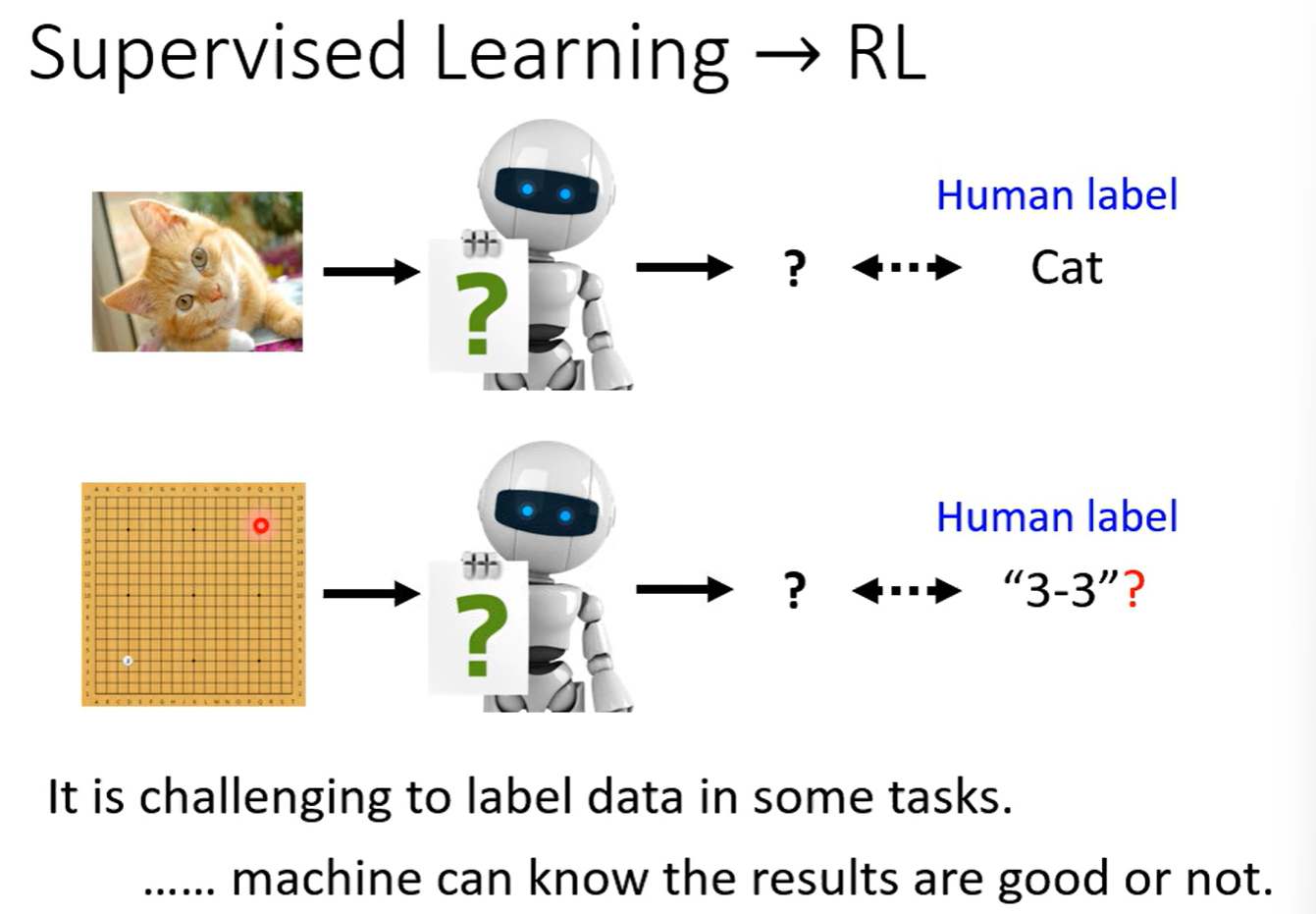
RL适合难以让人类来标注label的任务。
概念:类比ML的三个步骤
回顾ML本质:目的是拟合一个很棒的函数。那么RL其实也是在找一个函数。在RL里,有actor和environment 。它们会进行互动,actor会得到环境的 observation (观测) 作为输入。actor会对此输出,叫做action。action会影响environment,产生新的observation。
因此,类比ML的拟合函数的过程,其实actor就是我们在寻找的“函数”。环境给actor的reward,就能告诉它目前采取的action是好还是不好的。
这个函数的目标是,maximizes从environment获得的reward总和。

举个更具体的例子:游戏 space invader。

那么刚刚讲的概念,对应到这个游戏上就是:

围棋也是一个道理:

先回顾一下ML的三个步骤:
- 有未知数的函数
- 从训练data中,定义loss函数
- 优化器
对应过来,第一步,在RL里面,有未知数的函数就是actor (policy network) ,它的输入可以是一个游戏画面,输出可以是一个分类任务(例如,游戏的下一步操作)。
Network的架构就是人们自己来架构了。例如,如果输入与图像相关,那么就可以采用CNN;如果要回忆游戏整个进程来判断下一步的行为,就可以考虑用RNN或transformer来实现记忆。

第二步,定义loss函数。仍以刚才的游戏为例,从游戏开始得到结束的过程叫episode (指从环境中的一次完整的交互过程,从起始状态开始,一直到终止状态(或者达到最大步数)为止 的序列)。整场游戏每一步的reward加起来的total reward(称为return) 就是R,

第三步,optimization。trajectory(轨迹) 是指智能体与环境交互过程中,所经历的 状态、动作 序列。它描述了智能体在某次尝试中走过的完整路径。
optimization要调整actor的参数,让R越大越好。而reward也是一个函数,这看起来似乎与以往的任务相像,如下图,除了env、reward以外,图中都是各种线性、非线性的函数,那就有点像在优化一个RNN。

但RL的优化是很困难的,有这样三个问题:
- actor的输出是有随机性的,actor产生的a1、a2其实是通过sample产生的。输入相同,输出每次不一定一样。
- env和reward是黑盒,不知道里面的事情。在例子中,env是游戏机的机制,reward是游戏的规则。它们不是神经网络。
- 同时,env和reward的输出也是有随机性的,就像例子里的游戏机出现的画面与结果有随机性一样。
因此,不能用之前学过的方法来训练RL。如何optimization就是RL的难点。
这似乎与GAN有异曲同工之妙。当时我们处理GAN的时候,将generator和discriminator接在一起,控制它们某些时候的某些参数不变。reward就像discriminator。调整参数让R越大越好。
然而,GAN里面discriminator也是一个神经网络,是我们了解的结构,甚至是我们可以通过梯度下降训练的结构。而RL的随机性太大了。
Policy Gradient
如何操控actor的输出,让它在s的输入下,得到特殊的 $\hat{a}$ 输出呢?
回忆老方法,如果s情况下,左拐是最好操作,希望机器左拐,那就可以算一算交叉熵,让 L = e 即可,再
如果要让机器“不要采取某种操作”,L = -e 即可。
把两种L结合起来,就是,

等等!这不就回到 supervised learning 了吗! 上面这张图片,难道不就是两个 classification 任务吗?
这张图确实可以看为 supervised learning 。我们等会再讨论RL与 supervised learning 不同的地方。
那我们的训练 data 是什么?如图,以游戏为例,$s_N$ 是 image,$\hat{a}_N$ 是行动,$A_N$ 是执行程度良好程度(代表我们有多希望机器看到 $s_N$ 的时候,会多想做 $\hat{a}_N$ )。所以要用 $A_N$ 来乘上 $e_N$ ,求和作为 $L$ 。
我们接下来的问题,就是如何得到一组{ $s_N$ , $\hat{a}_N$ } 和 $A_N$ 。这是重点。
Version 0 :简单但不正确的版本
要得到数据,就要先收集一些s与a的pair。如何收集?先让actor与环境互动得到。很多个episode之后,如何评价一个pair好不好?最简单的方式是,如果这个pair经过reward的结果很好,就是好的action,反之不是好的。
那就是让 $A_N = r_N$ 。

但是,这样得到的actor会是一个很“短视 ”的actor,它只会知道“一直爽”。由于每一个行为不是独立的,都可能会影响接下来的互动,所以不能这么短视。这样的策略是有问题的。

在游戏的例子里,机器通过这种策略,只会学到疯狂开火。
现在要真正进入RL的领域了,来看看Policy Gradient(策略梯度) 是怎么做的。
Version 1
在 Version 1 里,$a_1$ 这个行为到底有多好,不再取决于 $r_1$ ,而是从 $r_1$ 到 $r_N$ 的累加,称为 $G_1$ 。

这被称为 cumulated reward(累计奖励) 。
但是, Version 1 似乎也存在问题。假设这个游戏进程非常的长呢?这时如果把 $r_N$ 归功于 $a_1$ ,而N远大于1,似乎就不合适。
我们来采用更好的方法。
Version 2
引入折扣因子(discount factor)γ∈[0,1) 来保证总和是有限的,有 $G_1’ = r_1 + \gamma r_2 + \gamma^2 r_3 + \dots$

折扣因子越接近于 1,智能体越注重长期回报;折扣因子越接近于 0,智能体越注重短期回报。
Version 3
“好”与“坏”是相对的。如果所有其他的 r 都大于10,那么某个 r 是10就是不好的。但是,按原来的策略,由于r > 0,机器仍然会鼓励r = 10 的行为。如何解决这样的问题?
让$G_1’$ 减去b (baseline,基准) 后,再作为A,如图,这样A就有正有负,

怎么设定一个好的b呢?我们在稍后讨论,这要用到$V^\theta(s)$ ,代表的是一个参数化的状态值函数 。
总体再回顾一下Policy Gradient 吧,

注意,data 的收集部分是在一个训练迭代过程的 for 循环里,这就是说,每次收集完资料之后,只会更新一次参数 ,如图,

这是因为,一次 data 采样是一个完整的过程,某个适合更新 $\theta^{i-1}$ 的参数,不一定适合用来更新 $\theta^i$ 。


所以,RL较为耗资源和时间。
这种“训练的actor”和“互动的actor”是同一个的操作,叫做On-policy(在线策略)。
另一种是off-policy(离线策略) ,好处在于不要一直收集资料,常使用PPO 。细节先不细讲。
假设有一个action(例如:开火)从来没有执行过,那么就不会得到此行为的reward。所以我们要让actor的初始化非常随机,例如enlarge output的entropy,或者向parameters上面加上noise。
exploration(探索) 指的就是智能体尝试新的或不确定的动作,以便更好地了解环境,从而发现可能获得更高奖励的策略。
Actor-Critic
在这之前,我们都是在让RL去学习出来一个actor,用于从状态 s 中选择动作 a,现在我们要让RL学习出来critic。
critic 的作用可以理解为:
给定 actor 当前的策略参数 θ,critic 学习一个函数,用于估计在观察到状态 s 并采取动作 a 时,这个选择的“价值”是多少,也就是 当前策略下的回报期望。
具体一点,来看这个critic:value function。它通过游戏画面来判断reward的期望。

注意V的上标θ,说明它的数值与actor有关。形象地说,一手好牌(一个很好的s)也救不了一个参数很烂的actor。
如何训练critic?有这些方法,
MC
游戏互动多轮,看到Sa,$V^\theta$就要和G‘a越近越好,其他同理。注,G‘指的是引入折扣因子的cumulated reward 。

TD
TD希望不用玩完整场游戏,希望通过看st、at、rt、st+1来更新参数。有的游戏很长,甚至不会结束,那么MC就很不合适。
TD通过一个Vθ的前后项关系式推导,我们可以明确,希望$V^\theta(s_t) - γV^\theta(s_{t+1})$ 与 $r_t$ 越接近越好。

对比
看看这个例子,

MC、TD算出来的$V^\theta(s_a)$ 是大相径庭的。这需要注意。
critic怎么用在训练上面?现在回到之前的地方,来把刚刚的“Version 3”更新一下。
Version 3.5
把b换为$V^\theta(s_t)$,

为什么?先看看 $V^\theta(s_t)$ 到底是什么意思,

其中 $V^\theta(s_t)$ 从状态$s_t$ 出发,通过某种distribution来sample出来的action所对应的G的平均。(是一个期望)
G‘t代表执行$a_t$ 的cumulated reward。
但是,为什么用一个G‘t sample而不用状态$s_t$ 的平均G呢?所以方法可以再“升级”。
Version 4

这就是advantage actor-critic (A2C)。
A2C在第一次学习时很容易让人误解。我要在笔记里再次强调一下这个概念,以免自己遗忘或混淆:
$V^\theta(s_t)$ 是通过机器学习学习出来的函数,
而不是通过真正枚举所有 G 轨迹硬算出来的,
是用 采样到的轨迹,构造出近似的目标值
然后通过优化损失函数去逼近这些“目标”。
目标是什么?就是At计算式的前两项,
$Target=r_t+γV^θ(s_t+1)$
$A(s_t,a_t)=Target−V^θ(s_t)$
我们把这个思路再总结一下,用一句话就是:
A2C 中的 Value Function $V^\theta(s_t) $ 是一个“估计器”,通过采样 + 训练,不断逼近期望回报 $\mathbb{E}[G | s_t]$
而$V^\theta(s_t)$ 的训练方法刚才也学过了,一般是基于TD。
训练tip
可以让Actor与Critic共用一部分network。为什么?比如,s是图片,那么可以都用CNN来处理,那图中绿色的network也许就是CNN,就可以共用来提取游戏图像的某些特征。

这让我联想到了我之前遇到的情景(点击链接🔗) ,这里面的【思考】部分,与此处相似。
DQN
DQN(Deep Q-Network)不是 actor-critic 架构,不存在 “critic 来做决策”。DQN 是基于 Q-learning 的方法,只有一个 Q-network 来做决策。
这里先不细说。
Reward Shaping
目前,我们都是拿actor与环境互动,得到reward,对reward进行整理(例如,刚刚的cumulated reward以及引入折扣因子),得到分数A,再教actor如何去做。
假设reward出现多数是零的情况怎么办呢?在这种情况下,actor无法学到任何东西,因为我们不知道action是好是坏。
下围棋似乎就是这样一种情况,每落一子,无法得到reward,只有最后结束棋局的一子,才会知道reward。
我们需要定义一些额外的reward帮助agent在这种情况下学习,这就是reward shaping。
类比一下以前的知识。回忆我之前学习的CNN,人们设计卷积核的时候,或多或少就采取了人为的思维方式:卷积核的感受野、滑动方式……这在CNN中被称为归纳偏置(Inductive Bias)。Reward Shaping也可以视为在做类似的事情,它通过人类设计的奖励信号,引导智能体更倾向于某类行为策略,从而改变了它的策略搜索空间和收敛路径。这相当于在学习过程中加入了“偏好”或“先验假设” 。
举一个实际例子吧。
实例:VizDoom游戏
VizDoom是一个第一人称射击游戏。如果只用“击杀敌人得分”“被击杀扣分”,很难训练出来agent。人们对agent的reward shaping是这样的,

可以看到一些有趣的设定,比如机器“待在原地”会扣分,而“移动”会加9乘10的-5次方的小小分数。
Curiosity
可以给机器加上“好奇心 ” 。加上这样的reward:如果机器在活动过程中,遇到“有意义的新东西”,就加分。
人们做实验,只采用这样的reward,就能让机器简单学会“超级马里奥”游戏。
No Reward. Learning from demonstration
假设没有reward,该如何是好?事实上,reward只有在类似电子游戏这样的任务中才比较好定义,而在现实中,reward的定义其实是非常困难的。例如,如果要训练自动驾驶,该怎么定义reward?
像刚才的reward shaping,就是依靠人类的智慧来设计reward让机器来执行。然而,人类设计的reward可能逻辑考虑不周,机器会“误解”这样的reward。
这里有一个极端的伦理例子:人们把“机器人保护人类”设为reward,可能会导致机器学会囚禁人类来进行保护,以此达到最大的reward。人定的reward不一定是最好的。
没有reward的情况下,机器与环境互动的方法叫做imitation learning 。假设actor可以与环境互动,但是不会获得reward。我们可以找一些expert去做示范,这些expert通常是人类。将人类的互动记录下来,这就是demonstration。这些示范用 $\hat{\tau}$ 来表示,每一个 $\hat{\tau}$ 就是一个export的trajectory状态序列。例如,自动驾驶的训练中,人类的行驶记录就是示范。
但,这不又成了supervised learning了吗?比如,看到某些画面,就要踩刹车;看到$s_i$ ,就要输出的$a_i$ 与人类的示范越近越好。这就被称为behavior cloning。
这样存在的问题是,
- expert只能提供有限的observation 。例如,如果不提供撞车后的处理方式,自动驾驶可能学习不到撞车后要停下来等待处理交通事故。
- 机器可能会学到人类的某些个人特征,而它不知道它的“老师”哪些是多余的行为,哪些是要学的行为。
这样的问题有一些解决方法,我们来看看。
Inverse Reinforcement Learning(IRL,逆强化学习)
Inverse Reinforcement Learning的想法是,通过expert 和 environment来学出来一个reward function。用这个学出来的reward function来找到optimal actor(在给定环境中学到了最优策略 的actor)。

来具体看看它的做法。

注意,这里的“老师的策略可以得到最好的reward”与“完全模仿老师的行为”不是等价的。
具体的算法如下,

这与GAN有异曲同工之妙。