BERT
BERT简介
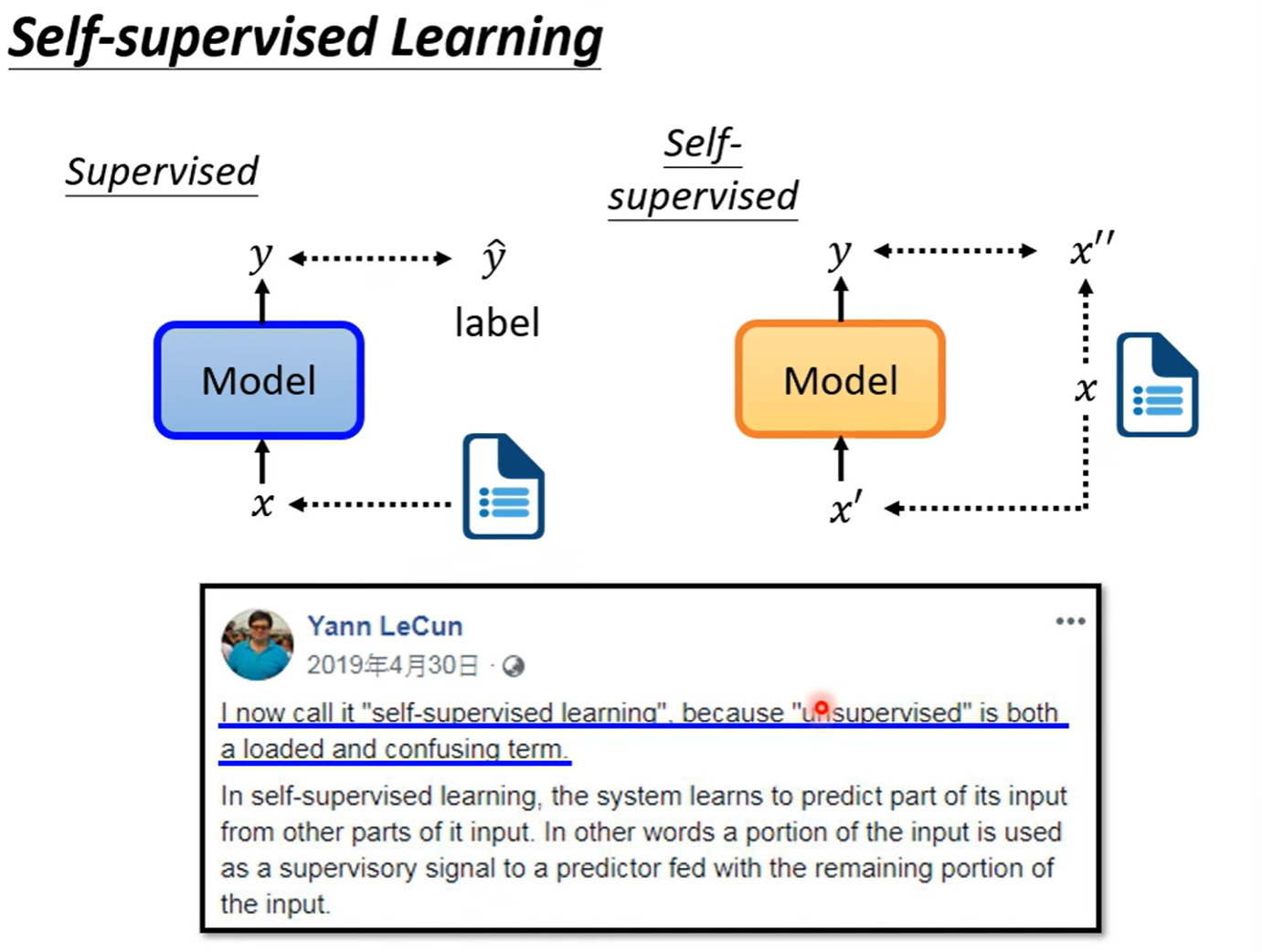
自监督
先看看什么是self-supervised learning,
预训练
BERT(Bidirectional Encoder Representations from Transformers)是一种transformer encoder。
随机masking掉里面一些tokens。这里mask有两种做法,一是将要mask的token换为一个special token,二是将它换为random token。具体用哪种?随机决定。接下来,以降低输出与Ground truth的交叉熵为目的训练BERT,

训练时,在做masking的同时,也会做另外一个事情:next sentence prediction。在网上收集很多句子,在两个句子加[sep]表示分隔,在开头加上[cls]。全部放入Bert,只取cls的输出,输出经过一个linear的transform后,得到yes or no的二元分类问题。这个 yes or no 的预测是,这两个句子是不是相接的。然而研究发现,next sentence prediction对接下来bert要做的事情(马上讲)帮助不大。
为什么没有用?可能是这个任务较为容易。人们发现了别的优化招数:SOP(sentence order prediction),让Bert分辨句子顺序。这个任务较为困难,也有较好的效果。

以上是bert的预训练机制。现在我们看看Bert怎么用。
BERT的使用
我们训练的时候,就让Bert在self-supervised learning学两个任务:masked token prediction 与 next sentence prediction。可以理解为Bert学会了做填空题。如何使用呢?Bert可以用在其他任务上:downstream tasks(下游任务)。
但做这些任务之前,要进行fine-tune(微调)。

| 阶段 | 数据类型 | 目的 | 是否有标签 |
|---|---|---|---|
| 预训练(Pretraining) | 大量通用文本 | 学语言能力 | ❌ 无需标签,自监督 |
| 微调(Fine-tuning) | 少量特定任务数据 | 适配任务 | ✅ 有标签,监督学习 |
在fine-tune之前的,就是pre-train。
让模型在GLUE(General Language Understanding Evaluation)的任务上分别fine-tune,平均得分可以看为它的综合表现。
Case 1
Bert到底怎么被使用?第一个任务例子是:输入一个sequence,输出一个类别。
例如,输入一句话,看看它的sentiment情绪。这就是 sentiment analysis任务。
这里,就需要提供下游任务的标注资料。所以这里的训练是Supervised Learning。又因为前面pre-train是Self-Supervised Learning,所以BERT是 半监督学习(Semi-Supervised Learning) 。
下游任务训练的时候,将bert与linear视为一个完整的模型,用gradient decent优化。其中,linear是random initialization的,而Bert,是我们刚刚pre-train来init的。

为什么要这么做?因为优化会做填空题的bert比优化random initialization的Bert好。
为什么呢?我询问了ChatGPT,它告诉我:
✅ 为什么使用预训练的 BERT 更好,而不是从零开始训练?
1️⃣ BERT 已经学会了语言的基本特性(比如句法、语法、上下文关系)
- 预训练的 BERT 在进行语言建模任务时,通过大量文本的学习,已经理解了单词的上下文和语言结构。
- 填空任务(Masked Language Model) 让 BERT 学会了如何根据上下文预测缺失的单词,这让它掌握了句子的语法结构、词汇的多义性等。
- 这意味着它已经积累了丰富的语言知识,就像是一个已经有了一些基本理解的学生。
2️⃣ 从零开始训练的 BERT 没有这些知识
- 如果我们从随机初始化开始训练模型(即没有任何预训练的知识),那么BERT会从头开始学习如何理解语言。
- 由于没有任何语言知识的先验,模型可能在训练初期需要更长时间来学习语言的基本规律,且可能容易过拟合或者学得不够好。
3️⃣ “填空题”技能给了 BERT 有力的“语言理解”基础
- 在预训练阶段,BERT通过填空任务(Masked Language Model)学会了根据上下文推测缺失的词汇,这实际上帮助它学会了很多关于语言的规律,比如:
- 词汇的上下文关系(比如 “apple” 和 “fruit” 在语境中通常相关)
- 句子的结构(例如主谓宾结构,修饰语的位置等)
- 这就像是一个学生通过做很多类似的题目,变得非常擅长理解和推理语言。
4️⃣ Fine-tuning 利用这些已有知识进行特定任务的调整
- 当你把预训练的 BERT 用于下游任务时,比如情感分析(sentiment analysis),它已经有了对语言的深刻理解。
- Fine-tuning 过程只是微调 BERT,让它更好地适应特定的任务。比如,通过提供标注好的情感分析数据,让 BERT 学会如何区分正面和负面情感。
- 相比从头训练,预训练的 BERT 模型在训练过程中能够更快地收敛,并且通常能达到更好的性能。
✅ 举个例子:
想象一下,你有一个学生,刚刚学过一些基本的数学(预训练),他已经知道了加法、减法等基本概念。然后你给他一个问题,要求他在这些基本知识的基础上做复杂的数学题(fine-tuning)。
如果他没有学过基本的数学知识,那么他就得从零开始学,这会非常困难和低效。
✅ 结论:
使用预训练的 BERT 更好,因为它已经掌握了很多语言的基础结构和语法规律,而不是从零开始学习。预训练的 BERT 在 fine-tuning 阶段能够利用这些已有的知识,从而更高效地解决下游任务。
数据对比如下:

Case 2:
这个任务要求,输入一个sequence,输出一个sequence,要求输入和输出的长度相等。
例如,输入一句英文,输出它的各个词性。这就是POS tagging(Part-Of-Speech Tagging)任务。

Case 3
输入两句sequence,输出一个class。
例如,Natural Language Inference(NLI)(自然语言推理/文本蕴含识别)任务,要求判断句子之间的逻辑关系。两个输入的sequence被称为:premise(前提),hypothesis(假设)。
模型要学会这两个句子是Entailment、Contradiction还是Neutral。这些关系是指:
Entailment(蕴含) :第二句可以从第一句推出。
Contradiction(矛盾) :第二句和第一句是矛盾的,不可能同时为真。
Neutral(中立) :第二句和第一句之间没有明确的逻辑关系,既不能推出也不矛盾。

Bert怎么解决这个问题?微调时,给它两个句子,开头加上[CLS],两个句子中间加上[SEP],取[CLS]对应的输出,放入一个linear,得到class。将得到的class与标注的资料求交叉熵作为loss来优化即可。
Case 4
这个任务要求做一个Extraction-based Question Answering 系统,即抽取式问答,问题的答案必须是从上下文中直接提取出来的一段文字 。
输入有文章,有问题;输出要求两个正整数s和e,代表从文章中第s个字到第e个字就是答案。D、Q、A的具体形式如图,

微调时,只需要对两个向量进行random initialized。这两个向量的大小与Bert的输出向量的维度是一样的。如何使用它们?先将第一个向量与【文章】对应的每一个输出进行点积,对算出的数值进行softmax。

得到分数最高的,那么s就等于对应的下标。
另一个向量也做同样的事情,得到e,

刚才提到的任务,都不是seq2seq的任务。如果要解决seq2seq的任务,如何进行预训练呢?BERT只预训练了encoder,可以预训练decoder吗?
预训练seq2seq模型
对encoder的输入故意进行一些扰动(Corrupt),让decoder来将seq修复成弄坏前的seq(reconstruct)。这样的任务设计就可以预训练好一个seq2seq模型了。
如何“弄坏”输入呢?例如MASS,把一些地方盖起来;还有很多别的方法。如果把他们都用,就是BART,

现在回到刚才来深入思考。为什么BERT这么有用?它明明只是训练了如何做填空题。
Why does BERT work?
解释是这样的:输入一串文字,得到的输出现在叫embedding。(输出得到的其实是contextual embedding,因为考虑到了上下文)

来看这样一个例子:对“果”上下文的不同,计算embedding的cosine similarity(余弦相似度):
先回顾一下之前学的内容,两个向量 $\mathbf{a}$ 和 $\mathbf{b}$ 的余弦相似度定义为:
- $\mathbf{a} \cdot \mathbf{b}$:向量点积
- $|\mathbf{a}|$、$|\mathbf{b}|$:向量的模(长度)
- $\theta$ 是它们夹角的余弦值

例子之间两两计算相似度,得到的结果是:

可见,BERT的embedding结果知道前五个苹果彼此相似,后五个苹果彼此相似。
所以,BERT输出得到的embedding向量就代表那个词的意思。而他的学习是从上下文学得的。在做填空题的过程中,Bert能从上下文了解词的意思。
然而,回顾以前的知识,可以回忆起之前学习的word embedding。其中的CBOW技术只用了linear而不是DL来词嵌入,因为要考虑到训练的效率。
BERT做到的就是contextualized word embedding。
| 维度 | CBOW | BERT(Bidirectional Encoder Representations from Transformers) |
|---|---|---|
| 模型类型 | 浅层神经网络 | 深层 Transformer 编码器 |
| 学习目标 | 给定上下文预测中心词 | 预测被 Mask 的词(Masked LM)+ 句子关系预测(NSP) |
| 上下文建模 | 局部上下文,静态建模 | 全句上下文,双向建模 |
| 词向量类型 | 静态(相同词总是同一向量) | 动态(根据上下文不同而变化) |
| 语义表达能力 | 基础语义,相似词聚类 | 高级语义,可区分歧义词 |
| 训练效率 | 高,资源消耗小 | 较低,计算资源消耗大 |
但,真的是这样吗?
BERT可以拿来做蛋白质、DNA、音乐分类。
但是,这里的BERT,可以是由English来pre-train的。 (将ATCG什么的DNA对应到某些英文单词上)

结果是,(红色BERT预训练,蓝色随机)

这说明里面的能力没有被人们研究清楚。
多语言BERT(Multilingual BERT)
用不同的语言先预训练BERT,再单独用English对Bert进行QA问答任务的微调,BERT居然自己学会了Chinese的问答任务。如图第四行,有78.8%的正确率。

为什么会这样呢?其实,多语言中,不同语言相似词汇的embedding在高维空间中很近,

但是,这又是为什么呢?明明BERT训练的时候,英文做英文填空,中文做中文填空,而不是混在一起的。
人们发现,将中文的词向量求平均,英文的词向量求平均,用中文平均词向量减去英文平均词向量,结果与两个相似的中文、英文词向量相减的结果相近。
这就是说,BERT在高维词嵌入空间中,似乎找到了一个方向,这个方向代表“从英文到中文”。如下图,

当然,上图只是演示,真正的情况是这样的,

GPT
预训练时,BERT做的事是填空,GPT做的事是预测下一个token。
不过,GPT和transformer的decoder一样,避免注意到当前位置之后的输入。

由于预训练就是在做预测任务,所以GPT的生成能力很强。不过,怎么把这种能力做微调,运用到其他任务上呢?可以和BERT一样,接个Linear,再接个分类头,然后进行微调。然而GPT的微调想法不是这样的,因为GPT的模型实在太大了,微调较难。
所以GPT的使用方式是:读题。告诉它这是什么题目,给出例子,给出prompt,让GPT自己生成。这就是Few-shot learning,但这不是learning,因为没有梯度下降,所以这是in-context learning。除此之外,还有one shot和zero shot。然而,测试结果与其他微调的模型相比,有些任务GPT的表现没有那么好。