首先,对ViT的结构做一个回顾
对于图片的读入,与CNN的卷积操作不同(不过,我们在下面的代码实现中,还是在用卷积对patch进行划分),ViT对图片进行embedding处理。
在原始论文里,Vision Transformer将图片打成很多个16 × 16的patch。将一个一个patch展平(flatten)后(从 16×16×3 → 768),再通过一个它们共享的FC层进行映射,得到固定维度的 embedding 向量,传给transformer。
可以把patch当成是NLP里面的单词tokens。
原论文中的结构如下:
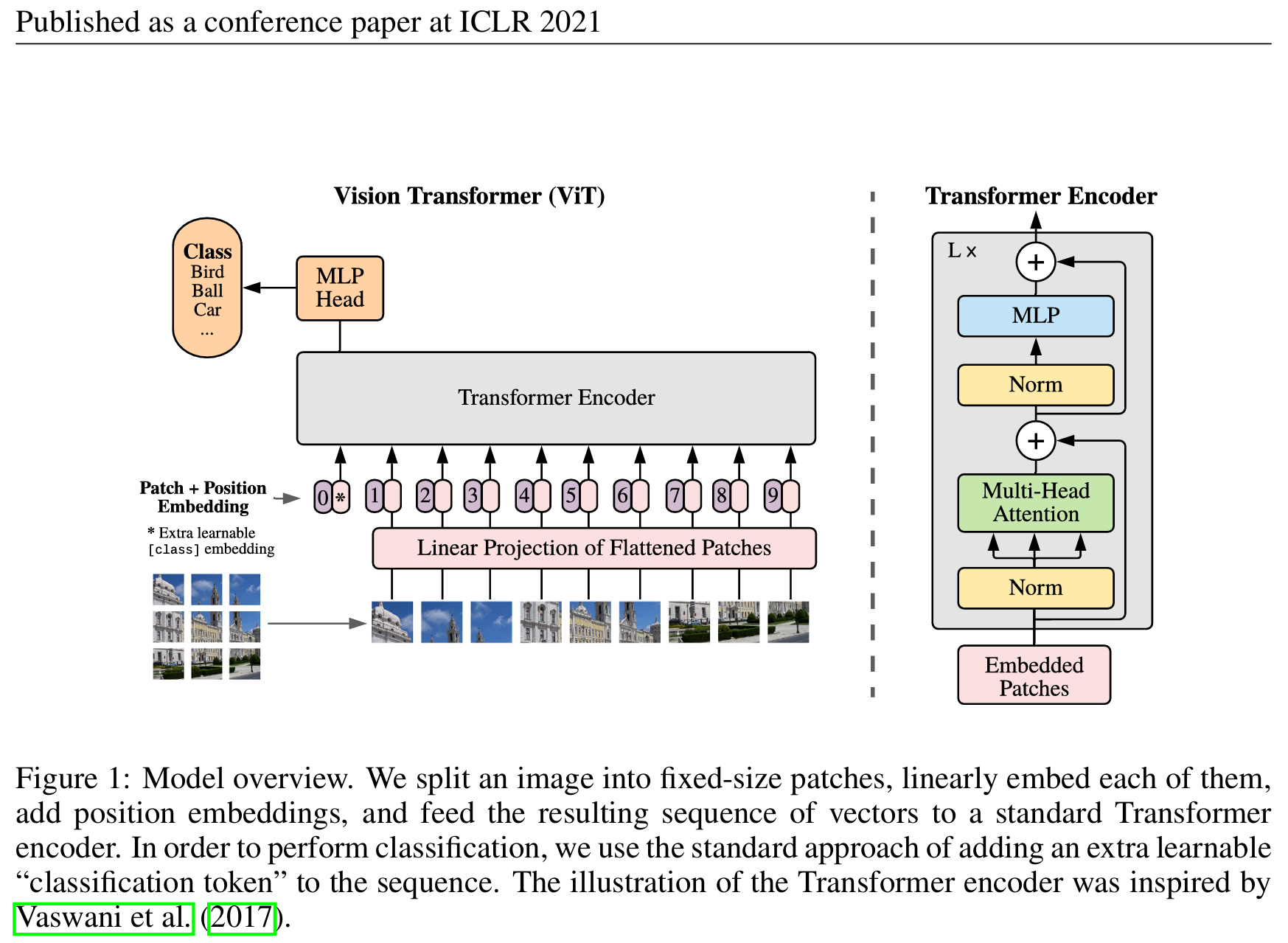
我们从图的左下角开始。先给定一张图,把它分成“九宫格”一样的小patch。我们使用卷积核对它划分,具体是把输入变成 (B, C, H’, W’) 的形状,其中,
B: batch sizeC: 通道数H': patch 的高度个数W': patch 的宽度个数
然后组合concatenate变成右边一个序列。之后,每个patch会被展平。
我们来具体看一下展平。在等会的代码实现中,我们使用的是
1 | nn.Flatten(start_dim=2, end_dim=3) |
展平的patch经过线性投射层(就是一个FC层,用大写E 表示)得到一个特征。这个过程就是patch embedding。
之后,也要像原来的transformer一样,加上位置编码来进行position embedding。现在整体的token就有原本的图像信息和位置信息了。
现在传给transformer encoder,但是用哪一个作为输出呢?借鉴BERT,加入特殊字符(图中为星号),位置信息为零。作者相信,此特殊字符可以在与序列中其他input的交互中学到有用的信息,并用来做分类任务。事实证明这是非常有用的,我在这篇笔记的最后会利用此特殊字符(CLS)来进行attention机制可视化的实现。
最后,再接上MLP分类头即可完成分类任务。
作者在右边放上了标准的transformer encoder结构。可以注意到,这与Attention Is All You Need 中的encoder相比,normalization被放到了多头注意力和多层感知机的前面 。我在之前的笔记里也提到过,对于这个encoder的设计有很多种。
MLP head起到了原来decoder的作用,因为不是复杂的生成任务,而是分类任务,所以它较为简单。
但需要注意的是,这里位置编码position embedding是怎么做的?答案是:是一个有多个向量的矩阵,每个向量代表某个位置的信息,维度为768,将对应某个位置的向量与原始patch经过FC层的输出相加 (要注意是相加)即可。
不过,与我之前的NLP的Transformer笔记矛盾的是 ,这个矩阵是可以被学习 的。NLP的原始Transformer确实用的是正弦/余弦函数生成的位置编码,不可学习 ,但具有良好的泛化能力,因为机器通过学习会关注每个 patch 之间的相对空间结构。在 ViT 里,实验却证明:可学习的位置编码效果更好 ,甚至可以从一维学习到二维的图像位置特征(就是说,机器可以通过学习,理解某个位置编号对应图像的某个二维位置,即这个patch为几行几列等等),而且实现也简单,所以 ViT 默认就用了它。
我复习了ViT的结构之后,就开始尝试复现它的代码。 过程如下。
论文复现与代码实现
先来回顾一下,对于数据的处理、模型的建立,需要经过哪些过程?
- 构建模型:
- 首先,构建transformer block,
class TransformerBlock(nn.Module):- 初始化TransformerBlock类:
def __init__(self, dim, heads, mlp_dim, dropout=0.1):,其中dim是输入的维度,heads是注意力头的数量,mlp_dim是MLP的维度,dropout是Dropout的dropout率 ,batch_first=True表示输入张量的第一个维度是batch_size。 - 定义TransformerBlock类的forward方法,用于前向传播:
def forward(self, x):,x代表输入的特征张量。
- 初始化TransformerBlock类:
- 然后,构建ViT模型:
class ViT(nn.Module):- ViT类的初始化方法,用于初始化ViT类:
def __init__(self, image_size=224, patch_size=16, num_classes=1000, dim=768, depth=12, heads=12, mlp_dim=3072, dropout=0.1):,image_size是输入的图像尺寸,patch_size是patch的大小,num_classes是分类的数量,dim是嵌入的维度,depth是Transformer块的数量,heads是注意力头的数量,mlp_dim是MLP的维度,dropout是Dropout的dropout率。 - 定义ViT的forward方法,用于前向传播:
def forward(self, x):,x是输入图像张量,通常形状是[batch_size, channels, height, width]
- ViT类的初始化方法,用于初始化ViT类:
- 首先,构建transformer block,
- 实例化model:
model = ViT(image_size=32, patch_size=4, num_classes=10, dim=512, depth=6, heads=8, mlp_dim=2048),针对CIFAR-10数据集调整参数:图像尺寸32x32,patch大小4x4,类别数10,嵌入维度512,6个TransformerBlock,8个注意力头,MLP维度2048 - 定义损失函数和优化器:
criterion = nn.CrossEntropyLoss()交叉熵损失optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.01)AdamW优化器,带权重衰减scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10)余弦退火学习率调度器,控制学习率的 - 数据增强和预处理:
- 官方的统计值是:
cifar10_mean = (0.4914, 0.4822, 0.4465)cifar10_std = (0.2470, 0.2435, 0.2616) - 设置
train_transform和test_transform,用来等会改变 - 加载 CIFAR-10 数据集
trainset = torchvision.datasets.CIFAR10(……)trainloader = torch.utils.data.DataLoader(……)testset = torchvision.datasets.CIFAR10(……)testloader = torch.utils.data.DataLoader(……)
- 官方的统计值是:
设置设备:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = model.to(device)将模型移动到GPU或CPU。训练模型:
for epoch in range(10):……,边训练边评估,model.eval(),with torch.no_grad():……
以上就是程序的整体流程,现在来做具体实现:
一、导入库
1 | import torch |
二、构建模型
① 构建transformer block
1 | class TransformerBlock(nn.Module): |
先初始化TransformerBlock类,
1 | def __init__(self, dim, heads, mlp_dim, dropout=0.1): # dim是输入的维度,heads是注意力头的数量,mlp_dim是MLP的维度,dropout是Dropout的dropout率 |
调用父类的构造函数,继承nn.Module ,
1 | super().__init__() |
初始化 TransformerBlock 的各个子模块,
1 | # 第一个层归一化 |
定义TransformerBlock类的forward方法,用于向前传播,
1 | def forward(self, x): #x代表输入的特征张量 |
② 构建Vision Transformer模型
1 | class ViT(nn.Module): |
初始化ViT类:
1 | def __init__(self, image_size=224, patch_size=16, num_classes=1000, dim=768, depth=12, heads=12, mlp_dim=3072, dropout=0.1): #这一段是ViT类的初始化方法,用于初始化ViT类,image_size是输入的图像尺寸,patch_size是patch的大小,num_classes是分类的数量,dim是嵌入的维度,depth是Transformer块的数量,heads是注意力头的数量,mlp_dim是MLP的维度,dropout是Dropout的dropout率 |
继承父类,
1 | super(ViT, self).__init__() |
把参数保存为实例属性,
1 | # 保存基本参数 |
断言异常情况,
1 | # 确保图像尺寸能被patch大小整除 |
构建其他模块,保存为实例属性,
1 | # 计算patch数量 |
定义前向传播方法,
1 | def forward(self, x): # 定义ViT的forward方法,用于前向传播 |
三、实例化model
1 | # 创建ViT模型实例 |
四、定义损失函数和优化器
1 | # 定义损失函数和优化器 |
五、数据增强和预处理:
① 保存官方的统计值
1 | # 数据增强和预处理 |
② 设置train_transform 和test_transform ,待会传递给dataset。
1 | train_transform = transforms.Compose([ |
但是,要注意测试集的预处理不需要水平翻转、裁剪、填充等操作。
1 | # 测试集的预处理(只做 ToTensor + Normalize) |
③ 加载 CIFAR-10 数据集
1 | # 3. 加载 CIFAR-10 数据集 |
六、设置设备
1 | # 设置设备(GPU或CPU) |
七、训练并评估模型
先开始循环,
1 | # 训练循环 |
获取训练集数据,转移到设备,
1 | inputs, labels = data # 获取训练集数据 |
前向传播,
1 | # 前向传播 |
反向传播,
1 | # 反向传播 |
下一步,要进行梯度裁剪,防止梯度爆炸。具体解释:对 model 中的所有参数的梯度进行裁剪(clip) 。如果梯度的 L2 范数总值超过了 1.0 ,就把它们按比例缩小,使总范数不超过 1.0。这样做可以防止梯度过大(爆炸)导致模型训练不稳定 。补充:对于一个向量
它的 L2 范数 是:
再补充一个问题:为什么会发生梯度爆炸?以此ViT模型为例,
网络太深:ViT 通常有 很多层 Transformer Block ,层数为depth。每一层都要参与反向传播,链式法则的乘法就非常多。如果每一层大于1的偏导数较多,多层累计起来,最终就可能指数级爆炸。
mlp 全连接层的激活函数 GELU 会放大梯度。
ViT 中哪些策略是为了防止爆炸的?
| 机制 | 在 ViT 中的作用 |
|---|---|
| LayerNorm | 保持输入输出分布稳定 |
| Dropout | 防止过拟合、限制激活放大 |
| 梯度裁剪(clip_grad) | 显式限制最大梯度 |
| warm-up 学习率 | 避免刚开始训练时“梯度突然暴涨” |
| 初始化方式 | 保证参数初始值不会导致爆炸传播 |
现在,来实现梯度裁剪,
1 | # 梯度裁剪,防止梯度爆炸 |
之后,更新参数,
1 | optimizer.step() # 更新参数 |
先累加损失,再每100个batch打印一次结果,
1 | # 打印训练信息 |
里层循环结束,现在在外层循环里更新学习率。这个scheduler是学习率调度器。在深度学习中,通常会随着训练的进行逐步 调整学习率 ,这种做法叫做 学习率调度 (Learning Rate Scheduling)。目的是:
避免训练初期学习率过大 ,导致模型不稳定。
防止训练后期学习率过小 ,让模型能更好地收敛。
调度器会按照规则动态更新学习率。放在外层循环里,根据 epoch 的进展来更新学习率。虽然scheduler 和 optimizer 是两个不同的实例,但是在定义时 optimizer 被传递给了scheduler ,scheduler.step() 让调度器通过访问 optimizer 的参数组(optimizer.param_groups)来更新学习率,就是
1 | # 更新学习率 |
现在不退出外层循环,而是在这个epoch的基础下,在测试集上评估模型,先做好基础设置,
1 | # 在测试集上评估模型 |
获取测试集数据,评估,
1 | for data in testloader: # 获取测试集数据 |
打印基于这个epoch的结果,
1 | print(f"Epoch {epoch + 1} - Accuracy: {100 * correct / total:.2f}%") |
八、保存模型权重
1 | torch.save(model.state_dict(), 'vit_cifar10.pth') |
基于运行代码的实验结果与总结
现在我开始运行程序,并记录一下实验现象。
下载cifar中…

犯了低级错误,num_workers > 0 ,使用 多进程 ,但是忘了写 __main__

赶快补上,
1 | if __name__ == "__main__": |
开始运行,

训练和评估模块都是正常的,我开始观察记录每一个epoch的accuracy,
1 | Files already downloaded and verified |
Accuracy最后只达到39.05%,似乎非常不顺利。我们来分析一下原因:
ViT模型本身特点:
- ViT 是设计给大数据集的(如 ImageNet),它没有 CNN 的局部感受野和归纳偏置。
- CIFAR-10 图像太小(32x32),切 patch 后的信息非常少,不容易学有效特征。
训练轮数太少:
- 模型还在下降 loss,accuracy 也在涨,明显是没收敛就被停了。
学习率可能过高或过低:
- transformer 非常敏感学习率。
我决定这样改正:
修改lr与weight_decay
1 | optimizer = optim.AdamW(model.parameters(), lr=5e-4, weight_decay=0.05) |
训练100轮,那么在100轮中lr逐渐退火到最低值,
1 | scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100) |
同时改一下for循环,
1 | for epoch in range(10): # 训练10轮 |
最后,加上可视化,
1 | import matplotlib.pyplot as plt |
在每个epoch结束后,
1 | train_losses.append(running_loss / num_train_batches) |
训练结束后,
1 | # 训练结束后,画图 |
关注loss与accuracy的可视化后,我还想关注这个:对于某一个特定的图片,transformer是如何分配注意力权重的。具体来说,每个 TransformerBlock 内部的 nn.MultiheadAttention 会计算 Query 、Key 和 Value
这里 X 就是所有 token 的矩阵,大小
注意力权重矩阵 A 就是:
其中 sqrt d 是缩放系数,这样A的形状是
表示每个 head、每个 query token 对每个 key token 的注意力分数。可视化热力图后,我们可以更直观地展示 CLS token 对各 patch 的权重分布。为什么只看CLS与其他patch?因为ViT 最终用 CLS token 的输出去做分类。最后点明细节:展示的是CLS token 作为 Query 与各 Patch 作为 Key 之间的相似度权重。
通俗来说,就是模型更关注图中哪一个小块。
这个注意力可视化程序我会单独写一个来实现。
好,现在修改好代码后,开始重新训练模型。
现在结束了,数据与可视化结果如下:

最后几个epoch的数据是
1 | [Epoch 96, Batch 100] Loss: 0.008 |
可以看到模型在90多的时候就逐步收敛了。现在模型的权重已经被我保存到了vit_cifar10.pth里面,让我再写一个程序来进行注意力可视化,只要把vit_cifar10.pth传递给它即可,
1 | import torch |
运行程序,就能调用刚刚训练出来的模型权重,进行图片识别,










可以看出来,模型注意到的地方(偏红色标记)与物体的特征高度相关,而模型“忽视”的地方(偏蓝色标记)常常是图片的背景与无关噪声。这说明ViT通过注意力机制真正学习到了物体的特征。
附录Ⅰ:源码
1 | import torch |
附录Ⅱ:参考文献
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al. “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale.” arXiv preprint arXiv:2010.11929, 2020.
https://arxiv.org/abs/2010.11929 - Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. arXiv preprint arXiv:1706.03762.
https://arxiv.org/abs/1706.03762 - PyTorch 官方文档. “torch.nn.MultiheadAttention.” 2025.
https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html